In an age of data-driven decision-making, the ability to transmute raw video footage into actionable insights is revolutionizing how businesses operate. But how does a computer “learn” to interpret video footage, much like a human? Let’s embark on a fascinating journey into the world of computer vision training, continuously drawing parallels to our own human perception.
Computer Vision Models: Seeing Like Humans
At a high level, a computer vision model emulates human vision, identifying and interpreting objects, movements, and patterns in images or videos. However, just as a child learns to recognize objects, faces, or actions through repeated exposure, a computer vision model needs training with a large amount of labeled data.
Let’s dive into the step-by-step process, comparing it to how we humans learn to see and understand our world.
Step 1: Collecting Data: Opening Our Eyes to the World
Our first step is collecting a wealth of video data, akin to how our eyes continually absorb our surroundings. For Kibsi, this might involve footage from retail stores, hospital lobbies, or manufacturing lines. Like a child learning to differentiate between various animals, we gather diverse and representative data to ensure our model can discern the different scenarios it will encounter.
Step 2: Preprocessing Data: Cleaning the Lens
Once we have our data, we preprocess it. Just as our brains automatically focus and adjust for lighting conditions when we view our environment, preprocessing formats the video footage into a form that our model can readily understand. Techniques like frame extraction and data augmentation ensure our model’s robustness, enabling it to handle different conditions, just like our adaptable human vision.
Step 3: Labeling Data: Naming What We See
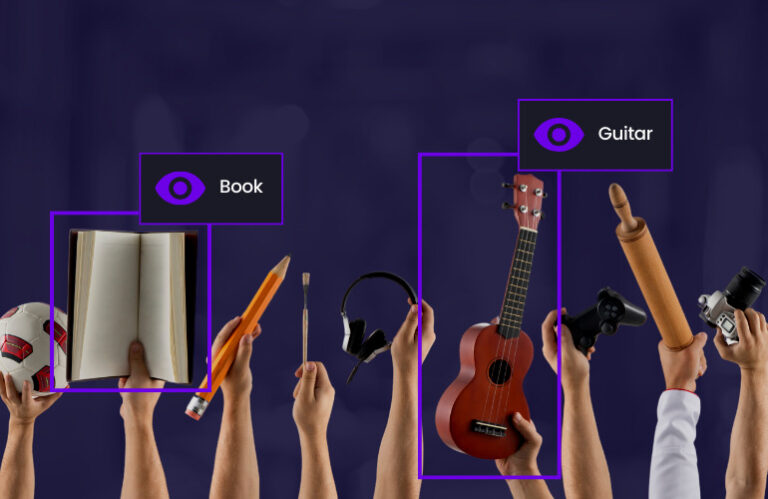
Next, we label the data. This mirrors how humans name what they see: a cat, a dog, or a car. Each frame is annotated with the relevant objects or events that the model needs to recognize. Accurate labeling is critical – it provides our model with its “language” of visual understanding.
Step 4: Training the Model: Learning to Recognize
With our data ready, we dive into training. The computer vision model, like a toddler, begins to identify patterns and features in the video frames. The model makes predictions, compares them with the ground truth labels, and refines itself using any discrepancies, much like a child learning to correct misidentifications over time.
Step 5: Evaluating and Fine-tuning the Model: Correcting Misinterpretations
Once training concludes, the model is tested on separate data. This mirrors our own process of learning from mistakes and adjusting our understanding accordingly. If the model struggles with certain types of data, it’s fine-tuned until it achieves an acceptable level of accuracy.
Step 6: Deployment and Continuous Learning: Gaining Experience
Once refined, our model is ready to encounter the world. But, much like a human, its learning doesn’t stop. As the model processes more data, it continues to refine its understanding and adapt to new situations.
Kibsi: Empowering Vision with Intelligence
Training computer vision models is a complex yet rewarding process akin to our own learning journey. Kibsi is at the forefront of this technology, offering tools to expedite the creation of new models, bringing a new dimension to video intelligence.
Kibsi’s platform can also use synthetic data to train models, vastly accelerating the training process. Synthetic data is artificially generated data that mimic real-world scenarios, providing diverse, high-quality training material in a fraction of the time. This is much like using flashcards to learn new words or concepts swiftly and efficiently.
In the vein of rapid and efficient processing, Kibsi also employs methods like YOLO (You Only Look Once), a real-time object detection system. Imagine a human brain identifying every object in a scene in a single glance without needing to scrutinize each detail separately – that’s what YOLO does for computer vision, making it a powerful tool for real-time video analysis.
Kibsi is not just a passive observer; its platform converts video feeds into structured data, providing critical insights that can be used for analysis or alerts. Think of it as going beyond just “seeing” to “understanding” – much like we humans don’t just view our world but make sense of it, making decisions based on our visual perceptions. Kibsi empowers organizations to make informed decisions based on real-time visual data.
Training computer vision models with Kibsi is akin to honing our human vision and comprehension but on a much larger and more sophisticated scale. It enables businesses to “see” their operations in a whole new light, unearthing insights previously hidden in unstructured video data.
As we continue to advance in the field of computer vision, the gap between human vision and machine perception keeps narrowing. With powerful platforms like Kibsi, we are not just training machines to see – we are empowering them with the intelligence to understand and act. Now that’s a sight to behold!
To learn more about how Kibsi can transform your business through video intelligence, contact us today.